Development¶
This module contains the classes
refactor, a module that assists in refactoring Modelica classes,Testerthat runs the unit tests of the Buildings library,Validatorthat validates the html code of the info section of the .mo files, andIBPSAthat synchronizes Modelica libraries with the IBPSA library.ErrorDictionarythat contains information about possible error strings.Comparatorthat compares the simulation performance across simulation tools or git branches.
Refactoring code¶
This module provides functions to
create Modelica packages and autopopulate for example the package.mo and package.order files
move Modelica classes include any associated .mos scripts, reference results and images, and
rewrite the package.order file.
- buildingspy.development.refactor.create_modelica_package(directory)¶
Create in directory a Modelica package.
If directory/package.mo exists, this method returns and does nothing. Otherwise, it creates the directory and populates it with a package.mo and package.order file.
- Parameters
directory – The directory in which the package is created.
- buildingspy.development.refactor.move_class(source, target)¶
Move the class from the source to the target name.
Both arguments need to be Modelica class names such as Buildings.Fluid.Sensors.TemperatureTwoPort, or a directory with a top-level package.mo file, such as Buildings/Fluid, that contains a file Buildings/Fluid/package.mo.
- Parameters
source – Class name of the source.
target – Class name of the target.
Usage: Type
>>> import buildingspy.development.refactor as r >>> old = "Buildings.Fluid.Movers.FlowControlled_dp" >>> new = "Buildings.Fluid.Movers.Flow_dp" >>> r.move_class(old, new)
- buildingspy.development.refactor.write_package_order(directory='.', recursive=False)¶
Write the package.order file in the directory directory.
Any existing package.order file will be overwritten.
- Parameters
directory – The name of the directory in which the package.order file will be written.
recursive – Set to True to recursively include all sub directories.
Usage: To rewrite package.order in the current directory, type
>>> import buildingspy.development.refactor as r >>> r.write_package_order(".")
Regression tests¶
- class buildingspy.development.regressiontest.Tester(check_html=True, tool='dymola', cleanup=True, comp_tool='funnel', tol=0.001, skip_verification=False, color=False, rewriteConfigurationFile=False)¶
Class that runs regression tests of the Modelica library.
Initiate with the following optional arguments:
- Parameters
check_html – Boolean (default
True). Specify whether to load tidylib and perform validation of html documentation.tool –
string {
'dymola','openmodelica','optimica'}. Default is'dymola', specifies the tool to use for running the regression test withrun().For
'dymola', this class uses the executabledmc, which is the Dymola version that does not require a graphical user interface to translate or simulate a model. dmc was introduced in Dymola 2025x. Ifdmcis not found on the system path, or if a simulation with a user interface is requested, then thedymolarather than thedmcexecutable is used.cleanup – Boolean (default
True). Specify whether to delete temporary directories.tol – float or dict (default=1E-3). Comparison tolerance If a float is provided, it is assigned to the absolute tolerance along x axis and to the absolute and relative tolerance along y axis. (If
comp_tool='legacy', only the absolute tolerance in y is used.) If a dict is provided, keys must conform withpyfunnel.compareAndReportarguments.skip_verification – Boolean (default
False). IfTrue, unit test results are not verified against reference points.color – Boolean (default
False). IfTrue, command line output will be in color (ignored on Windows).rewriteConfigurationFile – Boolean (default
False). IfTrue, rewrite conf.yml file. (Currently only supported for OpenModelica.)
This class can be used to run all regression tests.
Regression testing using Dymola
For Dymola, this module searches the directory
CURRENT_DIRECTORY/Resources/Scripts/Dymolafor all*.mosfiles that contain the stringsimulate, whereCURRENT_DIRECTORYis the name of the directory in which the Python script is started, as returned by the functiongetLibraryName(). All these files will be executed as part of the regression tests. Any variables or parameters that are plotted by these*.mosfiles will be compared to previous results that are stored inCURRENT_DIRECTORY/Resources/ReferenceResults/Dymola. If no reference results exist, then they will be created. Otherwise, the accuracy of the new results is compared to the reference results. If they differ by more than a prescibed tolerance, a plot such as the one below is shown.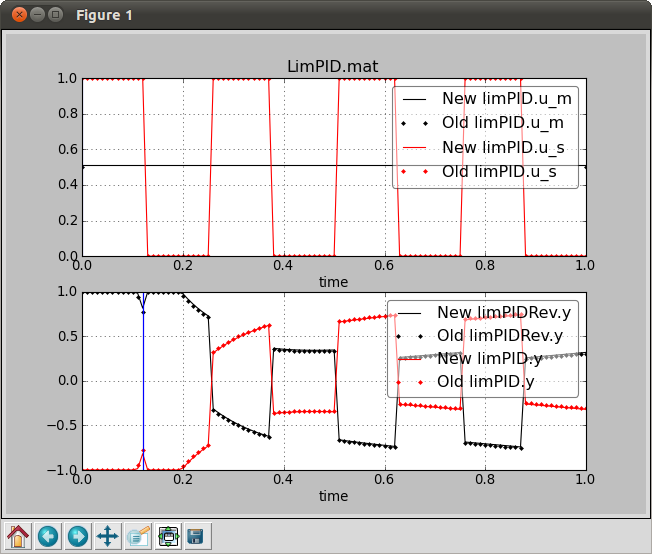
Plot that compares the new results (solid line) of the regression test with the old results (dotted line). The blue line indicates the time where the largest error occurs.¶
In this plot, the vertical line indicates the time where the biggest error occurs. The user is then asked to accept or reject the new results.
For Dymola, the regression tests also store and compare the following statistics for the initialization problem and the time domain simulation:
The number and the size of the linear system of equations,
the number and the size of the nonlinear system of equations, and
the number of the numerical Jacobians.
To run the regression tests, type
>>> import os >>> import buildingspy.development.regressiontest as r >>> rt = r.Tester(tool="dymola") >>> myMoLib = os.path.join("buildingspy", "tests", "MyModelicaLibrary") >>> rt.setLibraryRoot(myMoLib) >>> rt.run() MyModelicaLibrary.Examples.NoSolution: Excluded from simulation. Model excluded from simulation as it has no solution. Number of models : 11 blocks : 2 functions: 0 Using ... of ... processors to run unit tests for dymola. Generated 7 regression tests. Comparison files output by funnel are stored in the directory 'funnel_comp' of size ... MB. Run 'python -c "import buildingspy.development.regressiontest as t; t.Tester(tool=\"dymola\").report()"' to access a summary of the comparison results. Script that runs unit tests had 0 warnings and 0 errors. See 'simulator-dymola.log' for details. Unit tests completed successfully. Execution time = ...
To run regression tests only for a single package, call
setSinglePackage()prior torun().Regression testing using OpenModelica or OPTIMICA
For OpenModelica and OPTIMICA, the selection of test cases is done the same way as for Dymola. However, the solver tolerance is obtained from the .mo file by reading the annotation Tolerance=”value”.
For OpenModelica and OPTIMICA, a JSON file stored as
Resources/Scripts/BuildingsPy/conf.yml(or for backward compatibility, in conf.json) can be used to further configure tests. The file has the syntax below, whereopenmodelicaoroptimicaspecifies the tool.- model_name: Buildings.Fluid.Examples.FlowSystem.Simplified2 optimica: ncp: 500, rtol: 1E-6, solver: "CVode", simulate: True, translate: True, time_out: 600 comment: 'Add some comment and ideally a link to a github issue'
For OpenModelica, replace
optimicawithopenmodelica. For the detailed specification of allowed fields, seebuildingspy/templates/regressiontest_conf.py.Any entries are optional, and the entries shown above are the default values, except for the relative tolerance rtol which is read from the .mo file. However, with rtol, this value can be overwritten. Note that this syntax is still experimental and may be changed.
- areResultsEqual(tOld, yOld, tNew, yNew, varNam, data_idx)¶
Return True if the data series are equal within a tolerance.
- Parameters
tOld – List of old time values.
yOld – Old simulation results.
tNew – Time stamps of new results.
yNew – New simulation results.
varNam – Variable name, used for reporting.
filNam – File name, used for reporting.
model_name – Model name, used for reporting.
- Returns
A list with
Falseif the results are not equal, and the time of the maximum error, and an error message or None. In case of errors, the time of the maximum error may by None.
- are_statistics_equal(s1, s2)¶
Compare the simulation statistics s1 and s2 and return True if they are equal, or False otherwise.
- batchMode(batchMode, createNewReferenceResultsInBatchMode: bool = False)¶
Set the batch mode flag.
- Parameters
batchMode – Set to
Trueto run without interactive prompts and without plot windows.createNewReferenceResultsInBatchMode – Set to
Trueto create new results in batch mode. Default is False.
By default, the regression tests require the user to respond if results differ from previous simulations. This method can be used to run the script in batch mode, suppressing all prompts that require the user to enter a response. By default, if run in batch mode, no new results will be stored. To run the regression tests in batch mode, enter
>>> import os >>> import buildingspy.development.regressiontest as r >>> r = r.Tester() >>> r.batchMode(True) >>> r.run()
- checkPythonModuleAvailability()¶
Check whether all required python modules are installed.
If some modules are missing, then an ImportError is raised.
- deleteTemporaryDirectories(delete)¶
Flag, if set to
False, then the temporary directories will not be deleted after the regression tests are run.- Parameters
delete – Flag, set to
Falseto avoid the temporary directories to be deleted.
Unless this method is called prior to running the regression tests with
delete=False, all temporary directories will be deleted after the regression tests.
- static expand_packages(packages)¶
Expand the
packagesfrom the formA.{B,C}and returnA.B,A.C:param: packages: A list of packages
- format_float(value)¶
Return the argument in exponential notation, with non-significant zeros removed.
- getCoverage()¶
Analyse how many examples are tested. If
setSinglePackageis called before this function, only packages set will be included. Else, the whole library will be checked.- Returns:
The coverage rate in percent as float
The number of examples tested as int
The total number of examples as int
The list of models not tested as List[str]
The list of packages included in the analysis as List[str]
- Example:
>>> from buildingspy.development.regressiontest import Tester >>> import os >>> ut = Tester(tool='dymola') >>> myMoLib = os.path.join("buildingspy", "tests", "MyModelicaLibrary") >>> ut.setLibraryRoot(myMoLib) >>> ut.setSinglePackage('Examples') Regression tests are only run for the following package: Examples MyModelicaLibrary.Examples.NoSolution: Excluded from simulation. Model excluded from simulation as it has no solution. >>> coverage_result = ut.getCoverage()
- getLibraryName()¶
Return the name of the library that will be run by this regression test.
- Returns
The name of the library that will be run by this regression test.
- getModelicaCommand()¶
Return the name of the modelica executable.
- Returns
The name of the modelica executable.
- get_configuration_data_from_disk()¶
Read the configuration data conf.yml from disk and return it as an arry whose elements are json dictionaries.
- get_configuration_file_name()¶
Returns the full name of the conf.yml file.
- get_number_of_tests()¶
Returns the number of regression tests that will be run for the current library and configuration.
Note: Needs to be run within the run method (where elements of self._data requiring no simulation are first removed).
- static get_plot_variables(line)¶
For a string of the form *y={aa,bb,cc}*, optionally with whitespace characters, return the list [aa, bb, cc]. If the string does not contain y = …, return None.
A usage may be as follows. Note that the second call returns None as it has a different format.
>>> import buildingspy.development.regressiontest as r >>> r.Tester.get_plot_variables('y = {"a", "b", "c"}') ['a', 'b', 'c'] >>> r.Tester.get_plot_variables('... x}, y = {"a", "b", "c"}, z = {...') ['a', 'b', 'c'] >>> r.Tester.get_plot_variables("y=abc") is None True
- static get_tolerance(library_home, model_name)¶
Return the tolerance as read from the .mo file.
- Parameters
library_home – Home directory of the library.
model_name – Name of the model.
- get_unit_test_log_files()¶
Return the name of the logs files of the unit tests, such as
unitTests-openmodelica.log,unitTests-optimica.logorunitTests-dymola.logandsimulator-openmodelica.logetc.
- include_fmu_tests(fmu_export)¶
Sets a flag that, if
False, does not test the export of FMUs.- Parameters
fmu_export – Set to
Trueto test the export of FMUs (default), orFalseto not test the FMU export.
To run the unit tests but do not test the export of FMUs, type
>>> import os >>> import buildingspy.development.regressiontest as r >>> r = r.Tester() >>> r.include_fmu_tests(False) >>> r.run()
- isExecutable(program)¶
Return
Trueif theprogramis an executable
- static isValidLibrary(library_home)¶
- Returns true if the regression tester points to a valid library
that implements the scripts for the regression tests.
- Parameters
library_home – top-level directory of the library, such as
Buildings.- Returns
Trueif the library implements regression tests,Falseotherwise.
- pedanticModelica(pedanticModelica)¶
Set the pedantic Modelica mode flag.
- Parameters
pedanticModelica – Set to
Trueto run the unit tests in the pedantic Modelica mode.
By default, regression tests are run in non-pedantic Modelica mode. This however will be changed in the near future.
>>> import os >>> import buildingspy.development.regressiontest as r >>> r = r.Tester() >>> r.pedanticModelica(True) >>> r.run()
- printCoverage(coverage: float, n_tested_examples: int, n_examples: int, missing_examples: list, packages: list, printer: Optional[callable] = None) None¶
Print the output of getCoverage to inform about coverage rate and missing models. The default printer is the
reporter.writeOutput. If another printing method is required, e.g.printorlogging.info, it may be passed via theprinterargument.- Example:
>>> from buildingspy.development.regressiontest import Tester >>> import os >>> ut = Tester(tool='dymola') >>> myMoLib = os.path.join("buildingspy", "tests", "MyModelicaLibrary") >>> ut.setLibraryRoot(myMoLib) >>> ut.setSinglePackage('Examples') Regression tests are only run for the following package: Examples MyModelicaLibrary.Examples.NoSolution: Excluded from simulation. Model excluded from simulation as it has no solution. >>> coverage_result = ut.getCoverage() >>> ut.printCoverage(*coverage_result, printer=print) *** Model Coverage: 88 % *** You are testing: 7 out of 8 examples in package: Examples *** The following examples are not tested /Examples/ParameterEvaluation.mo
- printNumberOfClasses()¶
Print the number of models, blocks and functions to the standard output stream
- report(timeout=600, browser=None, autoraise=True, comp_file=None)¶
Builds and displays HTML report.
Serves until timeout (s) or KeyboardInterrupt.
- return_new_configuration_data_using_CI_results(configuration_data, simulator_log_file_json, tool, list_of_fmu_exports=None)¶
Compares the entry from the simulator_log_file_json with the configuration_data, and returns a new copy of configuration_data with changes to translate or simulate entries based on the CI tests. This method also removes comments if the translation or simulation was successful.
For models in the list list_of_fmu_exports, no entry about simulation will be added.
- run()¶
Run all regression tests and checks the results.
- Returns
0 if no errors and no warnings occurred during the regression tests, otherwise a non-zero value.
This method
creates temporary directories for each processors,
copies the directory
CURRENT_DIRECTORYinto these temporary directories,creates run scripts that run all regression tests,
runs these regression tests,
collects the dymola log files from each process,
writes the combined log file
unitTests-x.logto the current directory, where x is the name of the Modelica tool,for Dymola, compares the results of the new simulations with reference results that are stored in
Resources/ReferenceResults,writes the message Regression tests completed successfully. if no error occurred,
returns 0 if no errors and no warnings occurred, or non-zero otherwise.
- setDataDictionary(root_package=None)¶
Build the data structures that are needed to parse the output files.
- Param
root_package The name of the top-level package for which the files need to be parsed. Separate package names with a period.
- setLibraryRoot(rootDir)¶
Set the root directory of the library.
- Parameters
rootDir – The top-most directory of the library.
The root directory is the directory that contains the
Resourcesfolder and the top-levelpackage.mofile.- Usage: Type
>>> import os >>> import buildingspy.development.regressiontest as r >>> rt = r.Tester() >>> myMoLib = os.path.join("buildingspy", "tests", "MyModelicaLibrary") >>> rt.setLibraryRoot(myMoLib)
- setNumberOfThreads(number)¶
Set the number of parallel threads that are used to run the regression tests.
- Parameters
number – The number of parallel threads that are used to run the regression tests.
By default, the number of parallel threads are set to be equal to the number of processors of the computer.
- setSinglePackage(packageName)¶
Set the name of one or multiple Modelica package(s) to be tested.
- Parameters
packageName – The name of the package(s) to be tested.
Calling this method will cause the regression tests to run only for the examples in the package
packageName, and in all its sub-packages.For example:
If
packageName = IBPSA.Controls.Continuous.Examples, then a test of theIBPSAlibrary will run all examples inIBPSA.Controls.Continuous.Examples.If
packageName = IBPSA.Controls.Continuous.Examples,IBPSA.Controls.Continuous.Validation, then a test of theIBPSAlibrary will run all examples inIBPSA.Controls.Continuous.Examplesand inIBPSA.Controls.Continuous.Validation.
- showGUI(show=True)¶
Call this function to show the GUI of the simulator.
By default, the simulator runs without GUI
- useExistingResults(dirs)¶
This function allows to use existing results, as opposed to running a simulation.
- Parameters
dirs – A non-empty list of directories that contain existing results.
This method can be used for testing and debugging. If called, then no simulation is run. If the directories
['/tmp/tmp-Buildings-0-zABC44', '/tmp/tmp-Buildings-0-zQNS41']contain previous results, then this method can be used as>>> import buildingspy.development.regressiontest as r >>> l=['/tmp/tmp-Buildings-0-zABC44', '/tmp/tmp-Buildings-0-zQNS41'] >>> rt = r.Tester() >>> rt.useExistingResults(l) >>> rt.run()
- writeOpenModelicaResultDictionary()¶
Write in
Resources/Scripts/OpenModelica/compareVarsfiles whose name are the name of the example model, and whose content is:compareVars := { "controler.y", "sensor.T", "heater.Q_flow" };
These files are then used in the regression testing that is done by the OpenModelica development team.
Validator of syntax¶
- class buildingspy.development.validator.Validator¶
Class that validates
.mofiles for the correct html syntax.- validateExperimentSetup(root_dir)¶
Validate the experiment setup in
.moand.mosfiles.- Parameters
root_dir – Root directory.
- validateHTMLInPackage(rootDir)¶
This function recursively validates all
.mofiles in a package.If there is malformed html code in the
infoor therevisionsection, then this function write the error message of tidy to the standard output.Note that the line number correspond to an intermediate format (e.g., the output format of tidy), which may be different from the
.mofile.- Parameters
rootDir – The root directory of the package.
- Returns
str[] Warning/error messages from tidylib.
- Usage: Type
>>> import os >>> import buildingspy.development.validator as v >>> val = v.Validator() >>> myMoLib = os.path.join( "buildingspy", "tests", "MyModelicaLibrary") >>> # Get a list whose elements are the error strings >>> errStr = val.validateHTMLInPackage(myMoLib)
- validateHyperlinks(root_dir)¶
This function recursively searches in all
.mofiles in a package for broken Modelica hyperlinks.It searches for strings of the form
"modelica://some/file/name.png"and then checks whether some/file/name.png exits.If it does not exist, it returns an entry in the string of error messages str.
- Parameters
rootDir – The root directory of the package.
- Returns
str[] Error messages.
- Usage: Type
>>> import os >>> import buildingspy.development.validator as v >>> val = v.Validator() >>> myMoLib = os.path.join( "buildingspy", "tests", "MyModelicaLibrary") >>> # Check the library for broken links >>> errStr = val.validateHyperlinks(myMoLib)
Merging Modelica IBPSA Library¶
- class buildingspy.development.merger.IBPSA(ibpsa_dir, dest_dir)¶
Class that merges the Modelica IBPSA Library with other Modelica libraries.
Both libraries need to have the same package structure.
By default, the top-level packages Experimental and Obsolete are not included in the merge. This can be overwritten with the function
set_excluded_directories().- static filter_files(file_list, pattern)¶
Return
file_listfor those that matchpattern.Currently, pattern can contain at most one wildchar (‘*’) character.
- Parameters
file_list – List of files.
pattern – Pattern that is used to match files.
- A typical usage is
>>> import buildingspy.development.merger as m >>> m.IBPSA.filter_files(['a.txt', 'aa/b.txt', 'aa/bb/c.txt'], '*.txt') ['a.txt'] >>> m.IBPSA.filter_files(['a.txt', 'aa/b.txt', 'aa/bb/c.txt'], 'aa/*.txt') ['aa/b.txt'] >>> m.IBPSA.filter_files(['a.txt', 'aa/b1.txt', 'aa/b2.txt', 'aa/bb/c.txt'], 'aa/*.txt') ['aa/b1.txt', 'aa/b2.txt']
- merge(overwrite_reference_results=False)¶
Merge all files except the license file and the top-level
package.moWarning
This method is experimental. Do not use it without having a backup of your code.
This function merges the IBPSA library into other Modelica libraries.
In the top-level directory of the destination library, this function creates the file .copiedFiles.txt that lists all files that have been copied. In subsequent calls, this function deletes all files listed in .copiedFiles.txt, then merges the libraries, and creates a new version of .copiedFiles.txt. Therefore, if a model is moved in the IBPSA library, it will also be moved in the target library by deleting the old file and copying the new file.
This function will merge all Modelica files, Modelica scripts, regression results and images. An exception is the file IBPSA/package.mo, as libraries typically have their own top-level package file that contains their release notes and version information.
When copying the files, all references and file names that contain the string IBPSA will be renamed with the name of the top-level directory of the destination library. Afterwards, the package.order files will be regenerated, which allows libraries to have Modelica classes in the same directory as are used by the IBPSA library, as long as their name differs.
- Parameters
overwrite_reference_results – Boolean True causes the reference results to be overwritten, False causes the reference results to be skipped if they already exist. Note that if the reference result does not yet exist, it will be merged regardless of the setting of this parameter.
- A typical usage is
>>> import buildingspy.development.merger as m >>> import os >>> home = os.path.expanduser("~") >>> root = os.path.join(home, "test") >>> ibpsa_dir = os.path.join(root, "modelica", "IBPSA") >>> dest_dir = os.path.join(root, "modelica-buildings", "Buildings") >>> mer = m.IBPSA(ibpsa_dir, dest_dir) >>> mer.merge()
- static remove_library_specific_documentation(file_lines, library_name)¶
Remove library specific documentation.
For example, for the Buildings and IDEAS libraries, include the section in the commented block below, but keep the comment as an html-comment for other libraries.
<!-- @include_Buildings @include_IDEAS some documentation to be used for Buildings and IDEAS library only. -->
- Parameters
file_lines – The lines of the file to be merged.
- Returns
The lines of the files, with comments removed as indicated by the tag(s) in the comment line.
- static remove_library_specific_modelica_code(file_lines, library_name)¶
Remove library specific Modelica code.
For example, for the Buildings and IDEAS libraries, include the section in the commented block below, but remove the Modelica code for other libraries.
//@modelica_select @remove_Buildings @remove_IDEAS some code to be removed for Buildings and IDEAS libraries. //@modelica_select
- Parameters
file_lines – The lines of the file to be merged.
- Returns
The lines of the files, with code commented removed as indicated by the tag(s) in the comment line.
- set_excluded_directories(directories)¶
Set the directories that are excluded from the merge.
- Parameters
packages – A list of directories to be excluded.
Error dictionary¶
- class buildingspy.development.error_dictionary.ErrorDictionary¶
Class that contains data fields needed for the error checking of the regression tests.
If additional error messages need to be checked, then they should be added to the constructor of this class.
- get_dictionary()¶
Return the dictionary with all error data
- increment_counter(key)¶
Increment the error counter by one for the error type defined by key.
- Parameters
key – The json key of the error type.
- keys()¶
Return a copy of the dictionary’s list of keys.
- tool_messages()¶
Return a copy of the tool messages as a list.
Comparing simulation performance¶
- class buildingspy.development.simulationCompare.Comparator(tools, branches, package, repo, nPro=0, simulate=True, tolAbsTime=0.1, tolRelTime=0.1, postCloneCommand=None)¶
Class that compares various simulation statistics across tools or branches.
This class allows comparing various simulation performance indicators (CPU time, number of state events, number of Jacobian evaluations) across Modelica simulation tools and across git branches. The tests can be run across a whole library, or across an individual Modelica package. The results will be summarized in a table format that compares the performance across tools and branches.
Initiate with the following optional arguments:
- Parameters
tools – A list of tools to compare, such as
['openmodelica', 'dymola'].branches – A list of branches to compare, such as
['master', 'issueXXX'].package – Name of top-level package to compare, such as
BuildingsorBuildings.Examples.repo – Name of repository, such as
https://github.com/lbl-srg/modelica-buildings.nPro – Number of threads that are used to run the translations and simulations. Set to
0to use all processors.tolAbsTim – float (default
0.1). Absolute tolerance in time, if exceeded, results will be flagged in summary table.tolRelTim – float (default
0.1). Relative tolerance in time, if exceeded, results will be flagged in summary table.postCloneCommand – list. A list of a command and its arguments that is run after cloning the repository. The command is run from the root folder inside the repository, e.g., the folder that contains the
.gitfolder.
This class can be used to compare translation and simulation statistics across tools and branches. Note that only one simulation is done, hence the simulation time can vary from one run to another, and therefore indicates trends rather than exact comparison of computing time.
To run the comparison, type
>>> import os >>> import buildingspy.development.simulationCompare as sc >>> s = sc.Comparator( ... tools=['dymola', 'openmodelica'], ... branches=['master'], ... package='Buildings', ... repo='https://github.com/lbl-srg/modelica-buildings', ... postCloneCommand=[ ... "python", ... "Buildings/Resources/src/ThermalZones/install.py", ... "--binaries-for-os-only"]) >>> s.run()
To change the comparison for different tolerances without running the simulations again, type
>>> import os >>> import buildingspy.development.simulationCompare as sc >>> s = sc.Comparator( ... tools=['dymola', 'openmodelica'], ... branches=['master'], ... package='Buildings', ... repo='https://github.com/lbl-srg/modelica-buildings', ... postCloneCommand=[ ... "python", ... "Buildings/Resources/src/ThermalZones/install.py", ... "--binaries-for-os-only"]) >>> s.post_process(tolAbsTime=0.2, tolRelTime=0.2)
- post_process(tolAbsTime=None, tolRelTime=None)¶
Generate the html tables.
This function post-processes the simulations, generates the overview tables, and writes the tables to the directory results.
- Parameters
tolAbsTime – float. Optional argument for absolute tolerance in time, if exceeded, results will be flagged in summary table.
tolRelTime – float. Optional argument for relative tolerance in time, if exceeded, results will be flagged in summary table.
- run()¶
Run the comparison and generate the output.
The output files will be in the directory
results, and the raw test data are in the directories with the same names as specified by the parametertools.